

An Overview of GitOps
GitOps brings together the best practices of DevOps in application development and applies them to infrastructure automation. Diving into specifics of what the above line means let’s list down some of the DevOps best practices –
- version control,
- collaboration,
- compliance, and
- CI/CD tooling
When it comes to version control, GitOps makes Git Repository the single source of truth while delivering the infrastructure as code. When a code is submitted to Git Repo, it goes through all the necessary CI checks, followed by the CD process where all requirements like security, and necessary boundaries set for application development.
GitOps ensures:
- Standardized workflow for application development
- Security embedded throughout the application development process
- Enhanced reliability – when every change is tracked and recorded in the Git Repo enforcing transparency
- Consistency across all environments
We can combine different tools to build a GItOps framework. For instance, it can be git repositories, Kubernetes, CI/CD tools, and configuration management tools. Although we most commonly prefer to use Kubernetes with the GitOps framework, we can use it with any infrastructure as long as it is declaratively managed.
Why prefer GitOps?
For everyone who is invested in DevOps, GitOps provides a framework to realize the promises of DevOps. Enterprises practicing DevOps are seeing significant improvements in innovation velocity. From application development to deployment, management of application lifecycle and infrastructure configuration – maintaining stability and consistent performance throughout is how DevOps is making an impact.
Being familiar with Git-based workflows, GitOps expands the scope from application development to deployment, manages application lifecycle and infrastructure configuration. Every change to the code made throughout the lifecycle gets traced in the Git repo and is auditable.
The advantage for the Dev team –
Can code at their own pace, without being dependent on the resources to be approved/assigned by the operations team.
The advantage for the Ops team –
The ability to assess, trace and reproduce issues quickly to understand how the overall security might get affected. With Git being the source of truth, every modification committed is recorded and audited. Thereby, ensuring no unwanted change goes into production.
How GitOps works?
Declarative description
With GitOps we adopt the “everything as code” philosophy – let it be infrastructure, security, network anything. The fundamental principle of GitOps is to define the desired state of an infrastructure/application in its target environment i.e., following the declarative approach. This description now stays in the centralized Git repository – acting as the single source of truth. Thereby, bringing visibility across all departments.
Using the Git workflow as control
All the modifications or changes performed to the existing code happen in the Git files (through Pull request). Every detail is recorded, which can be reviewed or merged depending on the version control system. Git being a common software development tool for most software teams, has become the de facto standard of version control systems. To put it simply, the familiarity among developers also encourages them to participate in GitOps.
Separation of Configuration and deployment
There are automated processes to apply the required changes to the target environment. It is majorly recommended to go for a pull-based deployment where an agent/operator pulls and applies the changes.
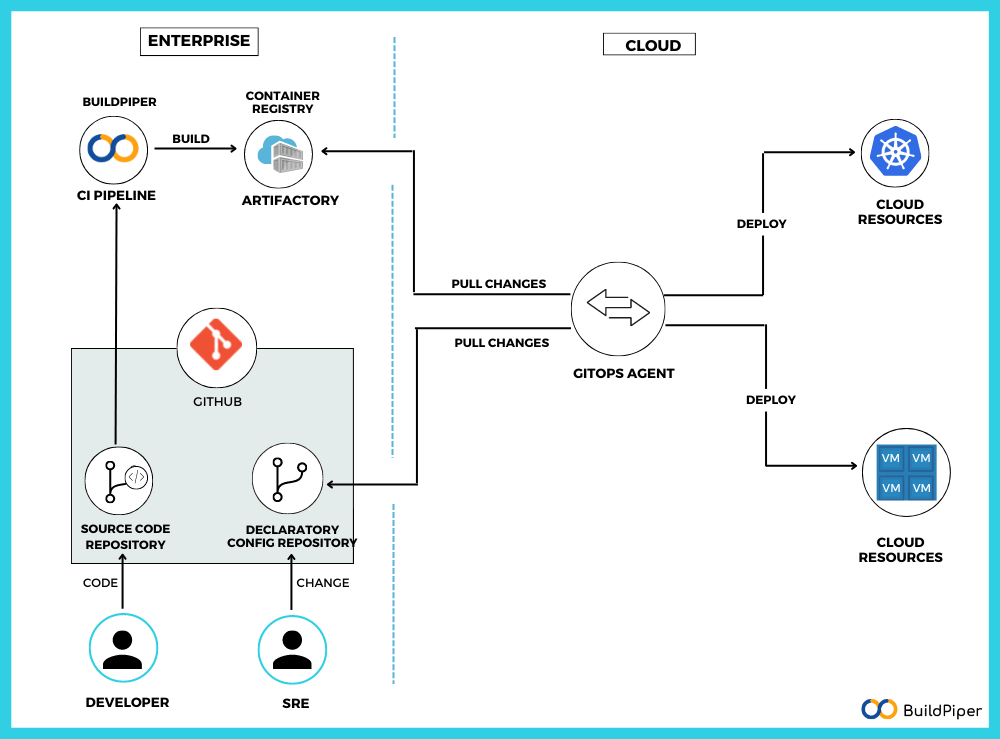
- In GitOps, both the application source code and the declarative configuration of the environment are stored in the Git repository.
- Developers’ side:
After reviewing the pull request, the developer changes the application source code and merges the changes. - This further triggers the CI pipeline where the new code is pushed to the Artifacts repository.
- Operations side:
The SRE team modifies the environment configuration in the Declarative Config Repo and after a subsequent review, merges all the changes. - The GitOps agent is a component that has been placed in the target environment. Now, the work of this component is to detect the changes and pull & apply these latest configurations to the target environment.
A point to note is that here we don’t require an operator to access the target environment. Thus, ensuring the credentials are stored within the environment.
Best Practices with GitOps
Go for Separate Repositories
The majority of teams who started with code and configuration together, understood quite early in the process that they’re better when dealt with separately. Reason?
- Application code and configuration information have independent lifecycles.
- Picture this, if we are changing the scale of deployment from 3 to 4 nodes, we don’t want a configuration change to trigger the rebuild of the application if our application code didn’t change.
- Adding on to that, the approval process of getting any specific change to the environment, shouldn’t hinder the continuous integration of application code changes.
Keep your Environments Separate with Different Directories
Just like the idea of keeping code and configuration separate, we also want the environments (pre-prod and prod environment) to be separated into different directories instead of branches. This might look like we are going against version control but if looked closely, it’s harder to keep track of changes in different environmental branches.
If you’re managing the workflows in different branches, the promotion from one environment to another can’t be done with a simple merge. Let’s say our application is built, tested, and ready to be moved from the sandbox environment to the testing environment. Here, we are considering a simple case of updating the image tag. Well, this update might have spurred different changes.
Now, when we go for a simple merge, then a lot of other details like ConfigMaps and Secrets (which also got modified) will also be introduced into different environments, where they are not supposed to be.
Here you might want to go for cherry-picking the manual changes. The problem with cherry-picking is that it might introduce significant configuration drift.
It’s completely fine if the environments are limited. But as we go further in adding new changes, with hundreds of different environments – it just makes the entire process impossible.
Use Trunk-based Development with K8s
When it comes to implementing GitOps with Kubernetes manifests it is highly recommended to use a trunk-based development workflow. In this method, one branch is defined as the Trunk and it carries out other modifications to each environment in different short-lived branches. When the development for the particular environment is completed, the developer creates a pull request from the trunk to these branches.
Also in this method, the developers can even create a fork to work on the environment, and then create a branch to merge the fork into the trunk after proper approvals through a pull request.
We can put it like this – the trunk-based development trades branches for directories. This can be seen as the trunk being the main branch or production.
Summing up all…
GitOps is not limited to containerized apps, it can even be applied to full-stack cloud resources. With well-designed automation processes in place, we can ensure more control over what goes into the production environment, the security of sensitive data, and transparency across all departments.
The transparency offered by GitOps does bring agility and collaboration to the Software development process. Adopting GitOps can be made seamless with GitOps-oriented CI-Sec-CD Pipelines. With the rise in No Code/Low Code platforms, reducing all these steps into a plug-n-play approach has been a huge help for the developers.
In other words, we can say that GitOps is an improved and more efficient version of DevOps. It’s an essential tool in the toolbox of all DevOps Engineers.


